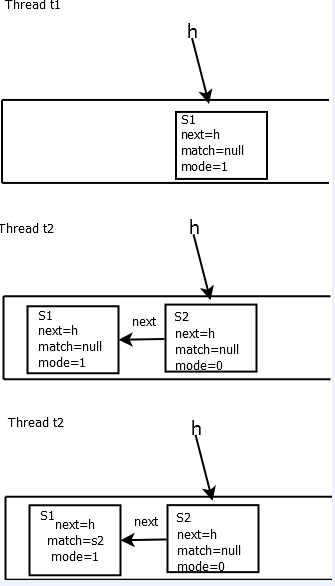
staticfinalclassSNode{ volatile SNode next; // next node in stack volatile SNode match; // the node matched to this volatile Thread waiter; // to control park/unpark Object item; // data; or null for REQUESTs int mode; }
Object transfer(Object e, boolean timed, long nanos){ SNode s = null; // constructed/reused as needed //e为null时,表示操作想从栈中获取数据,比如take方法 //e不为空时,表示携带数据入栈,如put方法 int mode = (e == null)? REQUEST : DATA; //自旋 for (;;) { SNode h = head; //头节点为空或匹配操作模式 if (h == null || h.mode == mode) { // empty or same-mode //等待超时版本,如put/take 的超时方法 if (timed && nanos <= 0) { // can't wait //如果头节点已经取消,换下一个节点 if (h != null && h.isCancelled()) casHead(h, h.next); // pop cancelled node else returnnull; } elseif (casHead(h, s = snode(s, e, h, mode))) {//构造s节点指向头节点 //等待对方线程满足匹配 SNode m = awaitFulfill(s, timed, nanos); if (m == s) { // wait was cancelled clean(s); returnnull; } //等待中返回后 if ((h = head) != null && h.next == s) casHead(h, s.next); // help s's fulfiller //如果为take操作,返回匹配的节点中的元素,put操作返回当前节点 return mode == REQUEST? m.item : s.item; } } elseif (!isFulfilling(h.mode)) { // try to fulfill,栈顶存在节点,如果为mode=0或1时 //头节点取消,把下一个节点替换头节点 if (h.isCancelled()) // already cancelled casHead(h, h.next); // pop and retry elseif (casHead(h, s=snode(s, e, h, FULFILLING|mode))) { for (;;) { // loop until matched or waiters disappear SNode m = s.next; // m is s's match if (m == null) { // all waiters are gone casHead(s, null); // pop fulfill node s = null; // use new node next time break; // restart main loop } SNode mn = m.next; //更新m,即对方线程的node的match节点为当前线程的节点s if (m.tryMatch(s)) { //两个节点都出栈 casHead(s, mn); // pop both s and m //如果是take操作,返回对方线程node中的元素,否则返回当前线程栈中的元素 return (mode == REQUEST)? m.item : s.item; } else// lost match s.casNext(m, mn); // help unlink } } } else { // help a fulfiller SNode m = h.next; // m is h's match if (m == null) // waiter is gone casHead(h, null); // pop fulfilling node else { SNode mn = m.next; if (m.tryMatch(h)) // help match casHead(h, mn); // pop both h and m else// lost match h.casNext(m, mn); // help unlink } } } }
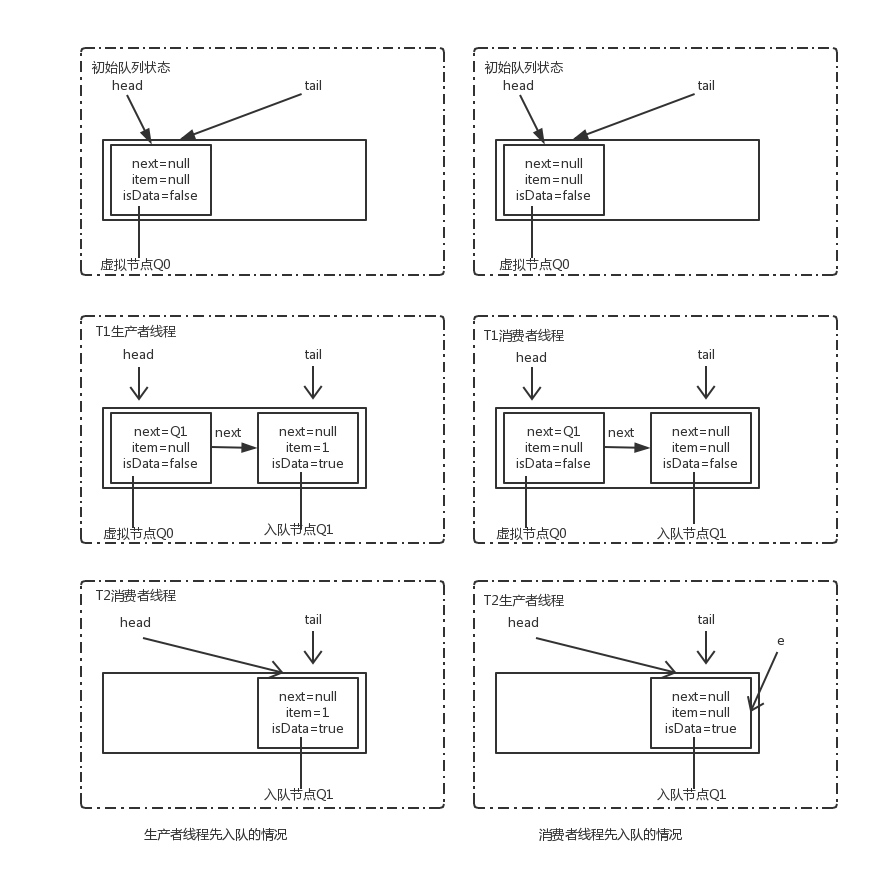
staticfinalclassQNode{ volatile QNode next; // next node in queue volatile Object item; // CAS'ed to or from null volatile Thread waiter; // to control park/unpark inal boolean isData; }
publicbooleanoffer(E e){ if (e == null) thrownew NullPointerException(); return transferer.transfer(e, true, 0) != null; } publicbooleanoffer(E o, long timeout, TimeUnit unit) throws InterruptedException { if (o == null) thrownew NullPointerException(); if (transferer.transfer(o, true, unit.toNanos(timeout)) != null) returntrue; if (!Thread.interrupted()) returnfalse; thrownew InterruptedException(); } publicvoidput(E o)throws InterruptedException { if (o == null) thrownew NullPointerException(); if (transferer.transfer(o, false, 0) == null) { Thread.interrupted(); thrownew InterruptedException(); } }
2、移除操作:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16
public E poll(){ return (E)transferer.transfer(null, true, 0); } public E poll(long timeout, TimeUnit unit)throws InterruptedException { Object e = transferer.transfer(null, true, unit.toNanos(timeout)); if (e != null || !Thread.interrupted()) return (E)e; thrownew InterruptedException(); } public E take()throws InterruptedException { Object e = transferer.transfer(null, false, 0); if (e != null) return (E)e; Thread.interrupted(); thrownew InterruptedException(); }